vsprintf
nginx
数据仓库
ZJSON2ABAPTYPE
PCB
产品运营
springboot
TableSQL
委托传值
多模态
网络管理
无线控制器
ATM系统
413
水仙花
mitmproxy
网上购书系统
serverless
CSS选择器
比较两个宽字符串的字符
requests
2024/4/11 19:42:56

Python中requests模块源码分析:requests是如何调用urllib3的
文章目录1. requests是怎么实现长链接的2. requests的Session作用是什么3. requests的模块在哪调用到了urllib34. Session类中的mount方法做了什么5. HTTPAdapter对象6. Session类的send函数调用adapters过程7. 相关文章1. requests是怎么实现长链接的
今天看一段代码的时候突…
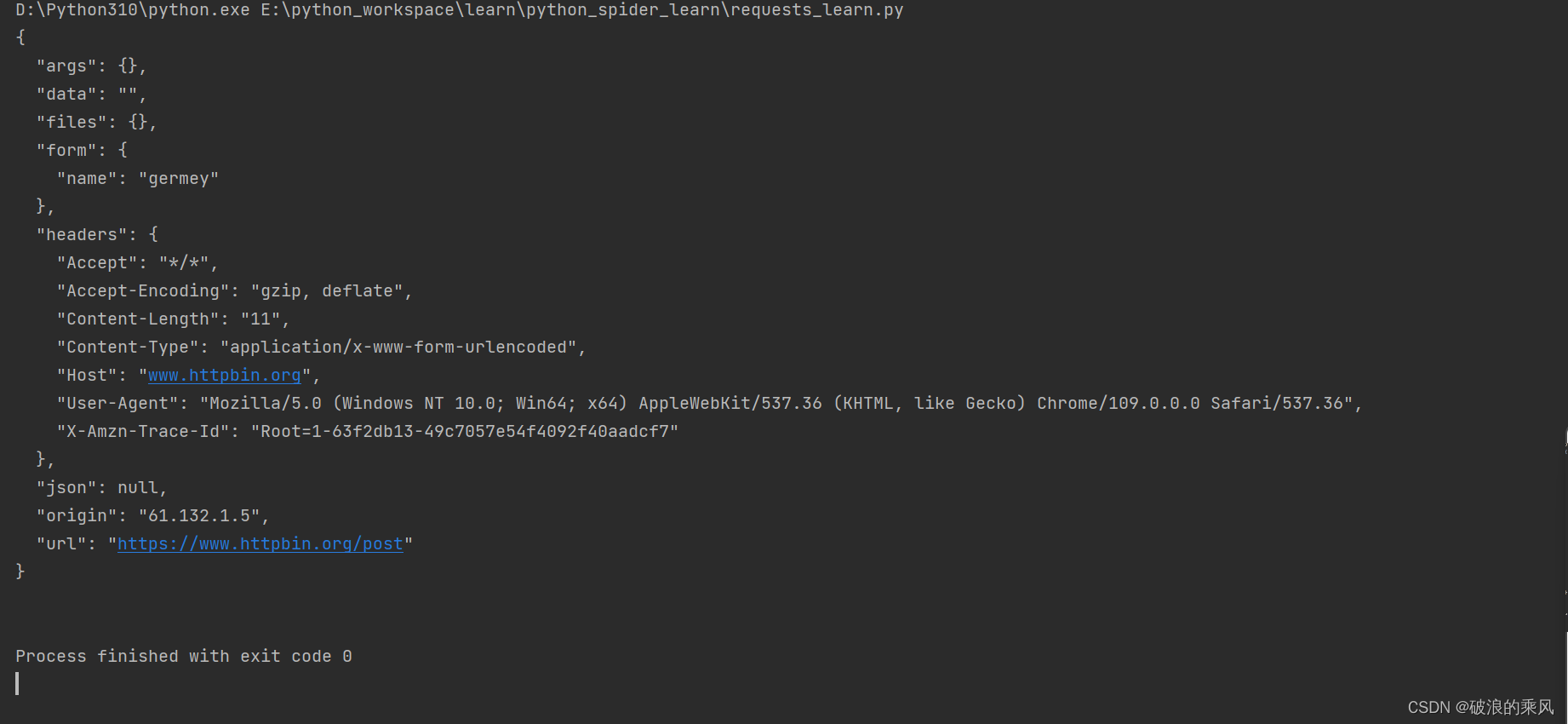
《python3网络爬虫开发实战 第二版》之基本库的使用-requests的使用 详解
文章目录1 requests库的使用1.1 准备工作1.2 实例引入1. 3 GET请求1.3.1 基本实例1.3.2 抓取网页1.3.3 抓取二进制数据1.3.4 添加请求头1.4 POST请求1.5 响应1.6 高级用法1.6.1 文件上传1.6.2 Cookie设置1.6.3 Session维持1.6.4 SSL证书验证1.6.5 超时设置1.6.6 身份认证1.6.7 …
致力于打造最详细的Requests使用(不定期补充)
Python 2.7 IDE Pycharm 5.0.3 Requests 2.10 是时候静心下来好好研究一下Requests了安装方法
我这里只说在PycharmAnaconda2下怎么添加requests包,至于如何在Pycharm下安装Anaconda2,请看zhusleep 和木子岚的回答 然后安装大概是这样的,…
requests 库(发送 http 请求)基本使用指南
概述
requests 是一个 Python 第三方库,用于发送 HTTP 请求。它提供了一种简单和方便的方法来与 Web 服务进行交互,如获取网页内容、发送数据、处理 Cookie 等。
requests 是 用 python 语言编写的,比 urllib2 模块更简洁requests 支持 HTT…
用requests方式爬取亚马逊Best sellers商品数据
亚马逊Best Sellers没有什么反爬机制,但有限制,就是爬着爬着就爬不动了,爬的类目也不多,就clothing这个类目,所以就将就用着,在里面加了个是否爬取,如果之前爬了就不爬了。 直接下代码ÿ…
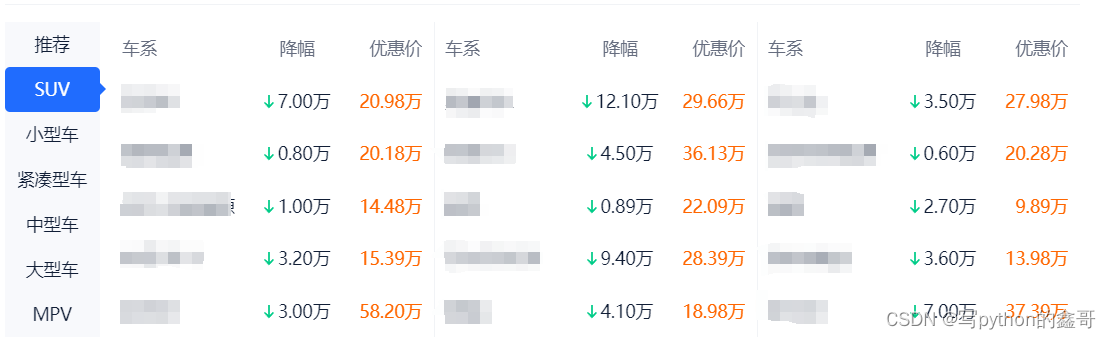
Python爬虫-获取汽车之家新车优惠价
前言 本文是该专栏的第10篇,后面会持续分享python爬虫案例干货,记得关注。
本文以汽车之家新车优惠价为例,获取各车型的优惠价,示例图如下: 地址:aHR0cHM6Ly9idXkuYXV0b2hvbWUuY29tLmNuLzAvMC8wLzQyMDAwMC80MjAxMDAvMC0wLTAtMS5odG1sI3B2YXJlYWlkPTIxMTMxOTU=
需求:获…
python的requests请求参数带files
踩坑接口请求参数含文件 requests接口请求既有file,也有json。划重点params requests
官网地址 https://requests.readthedocs.io/en/stable/user/quickstart/#post-a-multipart-encoded-file
接口请求既有file,也有json。划重点params
import reques…
python requests 另类post数据
0x00 问题1
在实际应用中,常常需要编写py脚本,对抓包所得到的数据包进行一些针对性(或者说要求的重放效果对于burpsuite不太方便直接实现)的重放攻击,我们知道在requests模块中,post数据的格式是dict&…

爬虫(三)lxml+requests(豆瓣Top250电影)
回家之后就不想学习了…
这次用的是lxml库,因为听说比起BeautifulSoup它的速度更快,然后就想了解一下。(全部的代码在最下面)
import库
from lxml import etree
import requests
import json
# from time import sleep
这是要…

如何获取美团的热门商品和服务
导语
美团是中国最大的生活服务平台之一,提供了各种各样的商品和服务,如美食、酒店、旅游、电影、娱乐等。如果你想了解美团的热门商品和服务,你可以使用爬虫技术来获取它们。本文将介绍如何使用Python和BeautifulSoup库来编写一个简单的爬虫…
【Python从入门到进阶】40、requests的基本使用
接上篇《39、使用Selenium自动验证滑块登录》 上一篇我们介绍了使用selenium进行滑块自动验证操作。本篇我们结束selenium的章节,来学习requests库的基本使用。
一、requests与urllib的爱恨情仇
1、requests与urllib的区别
大家在前面的学习中,访问网…

python-爬虫-requests
安装模块
pip install requests在jupyter notebook里使用ShiftTab查看
requests
requests库的主要方法
方法解释requests.requset()构造一个请求,支持以下各种方法requests.get()获取HTML的主要方法requests.head()获取HTML头部信息requests.post()向HTML网页提…
【小沐学Python】网络爬虫之urllib
文章目录 1、简介2、功能介绍2.1 urllib库和requests库2.2 urllib库的模块2.2.1 urllib.request2.2.2 urllib.error2.2.3 urllib.parse2.2.4 urllib.robotparser 2.3 入门示例 3、代码示例3.1 urlib 获取网页(1)3.2 urlib 获取网页(2) with header3.3 urllib post请求 4、urlli…
python3 requests库 base64算法加密图片
python3 requests库 base64加密图片
import requests
import os
import base64
session = requests.session()
url = http://ipadmin.zhaopingou.cn/add_userVerification_upload_zc
session.headers = {Host: ipadmin.zhaopingou.cn,User-Agent: Mozilla/5.0 (X11; Linux x…
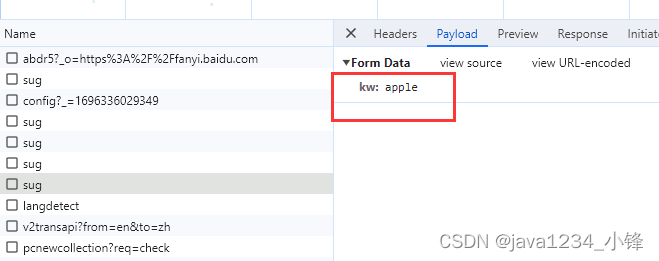
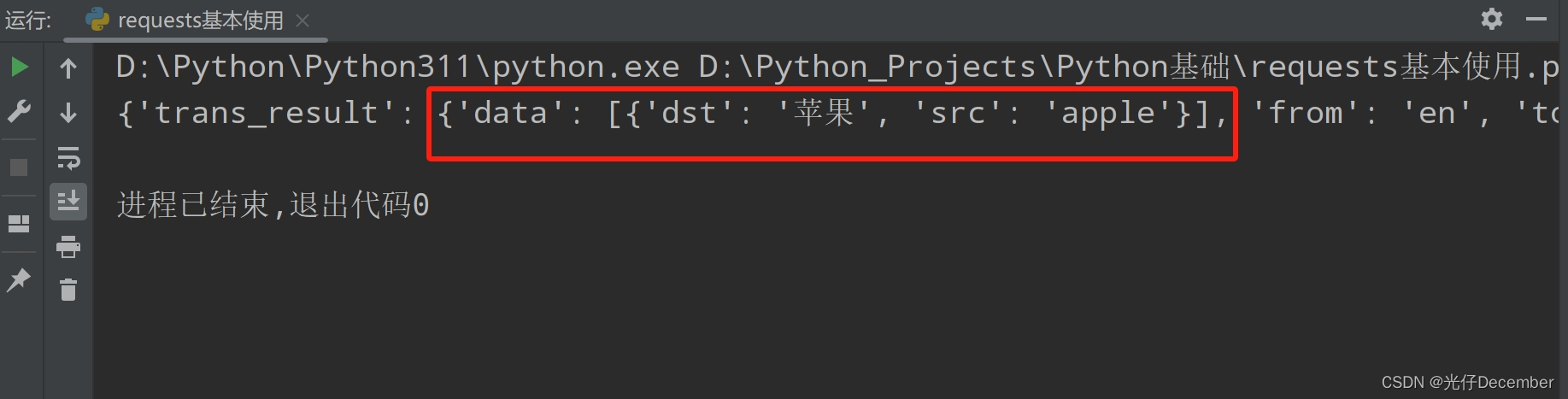
requests之post请求实例-百度翻译
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
打开百度翻译网址,我们输入需要翻译的英文,谷歌 F12 打开开发者工具,network可以看到网络请求,我们需要找到请求的API,…
requests之get请求实例-百度搜索
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
百度搜索请求地址:
https://www.baidu.com/s?wd宝马
如果我们直接用requests.get()进行访问,发现没有返回内容,因为百度服务器通过headers头…
Python requests之Cookie
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
在某些需要登录的网站或者或者应用,假如我们需要抓取登录后的内容,技术上本质通过session会话实现。服务器端存会话信息,浏览器通过Cookie携带…
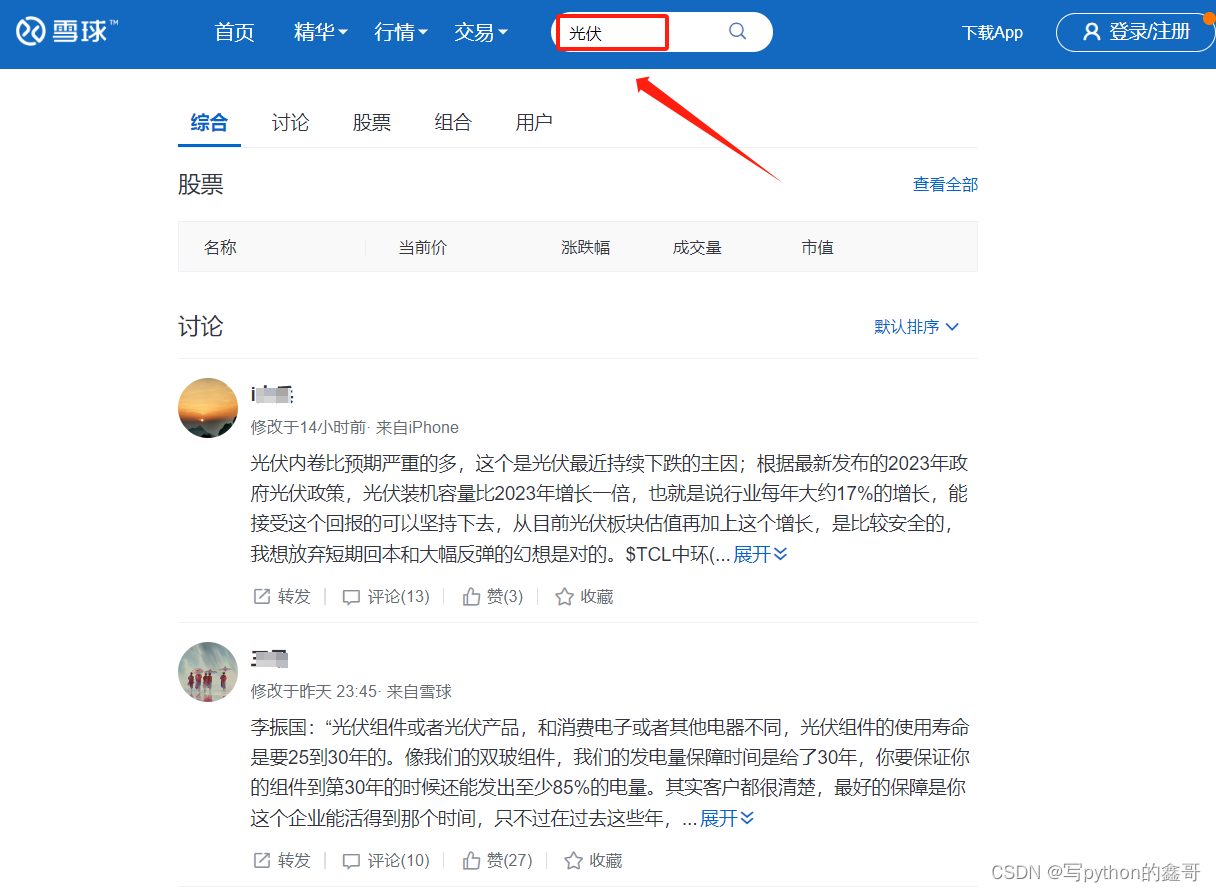
Python爬虫-雪球网
前言 本文是该专栏的第8篇,后面会持续分享python爬虫案例干货,记得关注。
地址:aHR0cHM6Ly94dWVxaXUuY29tLw==
需求:根据目标搜索词,获取搜索结果数据 废话不多说,跟着笔者直接往下看详细内容。(附带完整代码) 正文 1. 请求方式和参数分析
使用浏览器打开链接之后,…

爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1、网页分析
(1)分析 URL 规律
我们首先使用 Chrome 浏览器打开 豆瓣电影 Top250,很容易可以判断出网站是一个静态网页
然后我…
Python Requests安装
Python Requests安装
介绍一下如何安装Python的Requests模块 pip
推荐使用
Windows: pip install requests Linux: [sudo] pip install requests
easy_install
不推荐使用,只能安装,不能卸载,只能手动卸载模块
Windows: easy_install …
字体反爬-解析字体文件
字体反爬数据包的特征:
入门级字体反爬【高级KNN,OCR,
1.每一个网站的都不一样,可以理解是一种加密算法
2.是一种后缀为woff的文件
3.每一次请求的字体反爬数据都不一样,需要根据response实时获取到数据包的url,请求url,下载数据…

【Python从入门到进阶】43.验证码识别工具结合requests的使用
接上篇《42、使用requests的Cookie登录古诗文网站》 上一篇我们介绍了如何利用requests的Cookie登录古诗文网。本篇我们来学习如何使用验证码识别工具进行登录验证的自动识别。
一、图片验证码识别过程及手段
上一篇我们通过requests的session方法,带着原网页登录…
【小沐学Python】网络爬虫之requests
文章目录 1、简介2、requests方法2.1 get2.2 post 3、requests响应信息4、requests的get方法4.1 url4.2 headers4.3 params4.4 proxies4.5 verify4.6 timeout4.7 cookies4.8 身份验证 3、测试代码3.1 获取网页HTML(get)3.2 获取网页HTML(带he…

【Python_requests学习笔记(七)】基于requests模块 实现动态加载数据的爬取
基于requests模块 实现动态加载数据的爬取
前言
此篇文章中介绍基于requests模块 实现动态加载数据的爬取,并以 抓取Cocos中文社区中:热门主题下的帖子名称及id数据 为例进行讲解。
正文
1、需求梳理
抓取Cocos中文社区中:热门主题下的帖…
Python 之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息
Python之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息 目录
Python之 Http 获取网页的 html 数据,并去掉 html 格式等相关信息
request在爬虫中的常见使用情况
requests请求分为get请求和post请求。
get请求的常用参数包括:
urlself.url,paramsdata,headersself.headers
url -->请求的路径地址(字符串类型)
params-->请求的参数(字典类型)
headers-->设置请求头&#…
Python3 Requests第三方网络请求库
Python3 Requests第三方网络请求库 本文由 Luzhuo 编写,转发请保留该信息. 原文: https://blog.csdn.net/Rozol/article/details/79960568 以下代码以Python3.6.1为例 Less is more! #!/usr/bin/env python
# codingutf-8
__author__ Luzhuo
__date__ 2018/4/16第三方网络…

Python爬虫攻略(3)链家网爬虫 Selenium+Requests多线程
申明:本文对爬取的数据仅做学习使用,请勿使用爬取的数据做任何商业活动,侵删 本文是对上一篇文章中代码的优化: Python爬虫攻略(2)>Selenium多线程爬取链家网二手房信息
先上代码:
更多的信息在代码注释中
#!/usr/bin/env python
#-*- …

【Python爬虫】安装requests库解决报错问题
requests 确保pip的安装命令行下安装出现的问题以及解决办法换镜像源安装验证安装为什么使用requests库呢 废话不多说了,直接进入正题
确保pip的安装
首先要想安装requests库,第一点就是要确保pip已经安装。这个pip在Python高级版本中已经默认安装了。…
【Python】Python 中使用for循环取返回值 json 中的指定值
每天进步一点点~~
背景:最近在写接口自动化的案例,其中一个功能是在es里面造数,但是在造数前需要将原值清空,这样会更方便直接一些;查询接口会返回一个特定值:‘_id’,删除接口需要这个值进行指…

【Python_requests学习笔记(十)】基于requests模块实现Cookie模拟登录
基于requests模块实现Cookie模拟登录
前言
此篇文章中介绍基于 requests 模块实现 Cookie 模拟登录,并以模拟登录cocos中文社区(https://forum.cocos.org/)的个人登录页为例进行讲解。
正文
1、Cookie 和 Session
1.1、Cookie
Cookie &…
【Python_requests学习笔记(三)】requests模块中params参数用法
requests模块中params参数用法
前言
此篇文章中介绍requests模块中的查询参数params的详细用法和使用环境。
正文
1、params参数介绍
requests模块发送请求时,有两种携带参数的方法:1、params 2、data 其中,params在get请求中使用&#…
python windows环境下安装第三方requests和PIL
最近在研究python抓取数据,但是发现缺了个包requests。于是百度了遇到了好多坑,于是写了这篇文章来让大家安装第三库requests少遇到点坑。
首先进入http://docs.python-requests.org/en/latest/user/install/#install网址。 1.然后通过命令:…

【Python】requests库在CTFWeb题中的应用
目录
①Bugku-GET
②Bugku-POST
③实验吧-天下武功唯快不破
④Bugku-速度要快
⑤Bugku-秋名山车神
⑥Bugku-cookies ①Bugku-GET import requestsresprequests.get(urlhttp://114.67.175.224:12922/,params{what:flag})
print(resp.text)//或者
//resprequests.get(urlht…

AttributeError: module ‘lib‘ has no attribute ‘X509_V_FLAG_CB_ISSUER_CHECK‘解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…
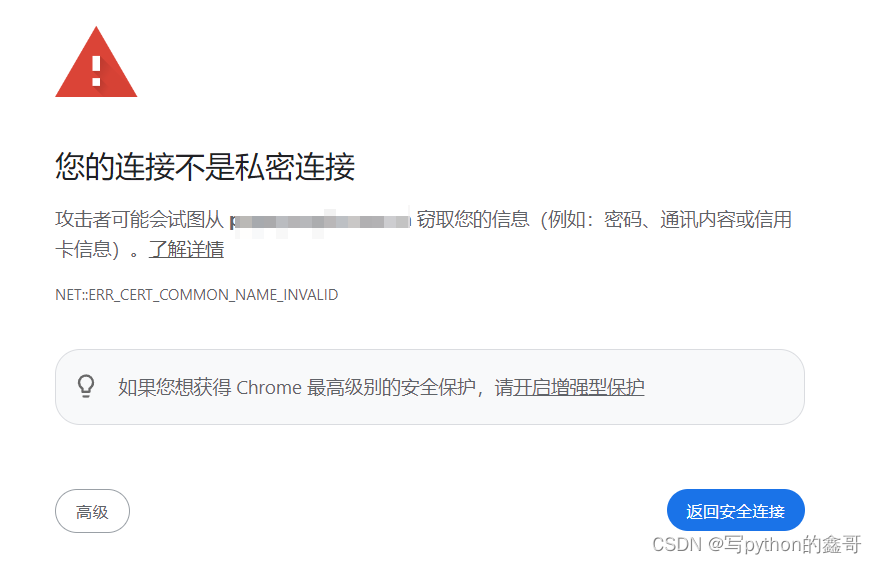
Python爬虫-解决使用requests,Pyppeteer,Selenium遇到网站显示“您的连接不是私密连接”的问题|疑难杂症解决(2)
前言 本文是该专栏的第13篇,后面会持续分享python爬虫案例干货,记得关注。
相信很多同学在处理爬虫项目的时候,会遇到一些网站出现如下图所示的情况: 就是当你不论是使用requests进行协议请求,还是使用自动化框架pyppeteer或者selenium都会出现上图中的情况。这相信会或多…
python的requests的使用
Python的requests库是一个非常常用的HTTP请求库,它可以方便地发送HTTP请求,处理响应结果。本文将详细讲解requests库的API和使用案例,并加上代码注释,方便大家学习。
requests库的安装
使用pip可以方便地安装requests库…

python web.py+requests 视频接收与发送
web.py是python中一个相对容易上手的web服务器搭建工具。
1 安装方式 web.py可以直接通过pip install 的方式安装即可,即:
pip install web.py
2 服务器 2.1 完整程序
import web #web.pyurls (/server , server, /.*, notfound #…
使用requests发请求操作Elasticsearch【一】
本文为博主原创,未经授权,严禁转载及使用。 本文链接:https://blog.csdn.net/zyooooxie/article/details/123730279
之前在测试环境查es数据,在用 Kibana;可下半年,因为某些原因 就不能用了。我就想着用代…

python requests接收chunked编码问题
很久以前写爬虫用C和libcurl来实现,体会了libcurl的复杂和强大,后来学会了python,才发现用pythonurllib/urllib2写爬虫比C来得容易,再后来发现了python的requests库,这个更简洁简单,只要懂HTTP和HTTPS就可以…
Python安装第三方库
Python安装第三方库 第一步:首先进入Python的安装目录,看一下在Python的安装目录下Scripts文件夹中有没有pip.exe的运行程序,dir打开,可以查找是否存在。如果有的话直接cmd界面输入Python安装目录,输入:pip install re…
爬虫系列(七) requests的基本使用
一、requests 简介
requests 是一个功能强大、简单易用的 HTTP 请求库,可以使用 pip install requests 命令进行安装
下面我们将会介绍 requests 中常用的方法,详细内容请参考 官方文档
二、requests 使用
在开始讲解前,先给大家提供一个…

爬虫系列(八) 用requests实现天气查询
这篇文章我们将使用 requests 调用天气查询接口,实现一个天气查询的小模块,下面先贴上最终的效果图 1、接口分析
虽然现在网络上有很多免费的天气查询接口,但是有很多网站都是需要注册登陆的,过程比较繁琐
几经艰辛,…

爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1、网页分析
(1)翻页
我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析,这里示例为《一出好戏》…
基于python的爬虫方法总结(一)
爬取的方法很多,,但是不管用什么方法总结起来就3大步
确定要爬取的URL地址向网站发请求获取相应的HTML页面提取HTML页面中有用的数据 文章目录一,获取静态页面数据方法urllib方法requests方法selenium方法BeautifulSoup方法Scrapy框架方法二…
Python爬虫实战-批量爬取美女图片网下载图片
大家好,我是python222小锋老师。
近日锋哥又卷了一波Python实战课程-批量爬取美女图片网下载图片,主要是巩固下Python爬虫基础
视频版教程:
Python爬虫实战-批量爬取美女图片网下载图片 视频教程_哔哩哔哩_bilibiliPython爬虫实战-批量爬取…
Python 同、异步HTTP客户端封装:性能与简洁性的较量
一、前言
引入异步编程趋势:Python的异步编程正变得越来越流行。在过去,同步的HTTP请求已经不足以满足对性能的要求。异步HTTP客户端库的流行:目前,有许多第三方库已经实现了异步HTTP客户端,如aiohttp和httpx等。然而…

大学生的小乐趣:python网页爬虫
网页Dev 网络爬虫主要看在网页的检查元素的这两个页面(Element、Network) Element :index页面的源代码(并且能进行快速的查找) Network:查找客户端和服务端之间的各种流
python Code
python里面含有多种框…
python实现自动刷平台学时
背景
前一阵子有个朋友让我帮给小忙,因为他每学期都要看视频刷学时,一门平均需要刷500分钟,一学期有3-4门需要刷的。 如果是手动刷的话,比较麻烦,能否帮他做成自动化的。搞成功的话请我吃饭。为了这顿饭,咱…
pandas教程:Hierarchical Indexing 分层索引、排序和统计
文章目录 Chapter 8 Data Wrangling: Join, Combine, and Reshape(数据加工:加入, 结合, 变型)8.1 Hierarchical Indexing(分层索引)1 Reordering and Sorting Levels(重排序和层级排序)2 Summa…
二、爬虫-爬取肯德基在北京的店铺地址
1、算法框架解释 针对这个案例,现在对爬虫的基础使用做总结如下: 1、算法框架 (1)设定传入参数 ~url: 当前整个页面的url:当前页面的网址 当前页面某个局部的url:打开检查 ~data:需要爬取数据的关键字&…
Python requests有问题
1问题1
今天使用脚本爬取某网站的接口,发现使用nodejs、postman和chrome可以正确获取数据,使用Python requests却返回405,没办法,只能使用nodejs和popen,通过nodejs的https模块获取接口数据以后,使用popen…

摸鱼工具—终端热搜榜,实在是上班摸鱼必备之工具,妙啊
本文介绍我用Python语言开发的热搜榜,聚合有百度、头条、微博、知乎和CSDN等网站热搜信息。该工具运行于终端中,比如cmder、powershell或者git bash等,实在是上班、摸鱼之必备工具。
—、工具执行效果 1.1 项目代码
项目代码地址存在gitee中…
Python requests之代理
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
很多网站和应用都有反爬虫策略,我们频繁的访问,一旦触发反爬虫策略,我们的IP就会被封掉。
我们为了应对反爬虫,可以使用代理。
代…
python web.py+requests 图片接收与发送
web.py是python中一个相对容易上手的web服务器搭建工具。
1 安装方式 web.py可以直接通过pip install 的方式安装即可,即:
pip install web.py
2 服务器 2.1 完整程序
import web #web.pyurls (/server , server, /.*, notfound #…

利用爬虫技术自动化采集汽车之家的车型参数数据
导语
汽车之家是一个专业的汽车网站,提供了丰富的汽车信息,包括车型参数、图片、视频、评测、报价等。如果我们想要获取这些信息,我们可以通过浏览器手动访问网站,或者利用爬虫技术自动化采集数据。本文将介绍如何使用Python编写…
爬虫(一)request和BeautifulSoup
先说明,我也是新手。我也是昨晚突然有兴趣才看的爬虫。我是在知乎找的教程。改动很少(有一句扑街了,我改了)。
主要是想记录理解的东西。Show the Code:
import requests
from bs4 import BeautifulSoupcomments []
r request…

一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
大家好,我是python222小锋老师。前段时间卷了一套 Python3零基础7天入门实战 以及1小时掌握Python操作Mysql数据库之pymysql模块技术
近日锋哥又卷了一波课程,python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium,文字版视频版。1…
Python爬虫-requests.exceptions.SSLError: HTTPSConnectionPool疑难杂症解决(1)
前言 本文是该专栏的第7篇,后面会持续分享python爬虫案例干货,记得关注。
在爬虫项目开发中,偶尔可能会遇到SSL验证问题“requests.exceptions.SSLError: HTTPSConnectionPool(host=www.xxxxxx.com, port=443): Max retries exceeded with url ...”。亦或是验证之后的提示…
requests模块简介及安装
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
Requests是一个优秀的Http开发库,支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码&am…
pandas教程:Interacting with Web APIs API和数据库的交互
文章目录 6.3 Interacting with Web APIs (网络相关的API交互)6.4 Interacting with Databases(与数据库的交互) 6.3 Interacting with Web APIs (网络相关的API交互)
很多网站都有公开的API,通过JSON等格式提供数据流。有很多方法可以访问这些API,这里…
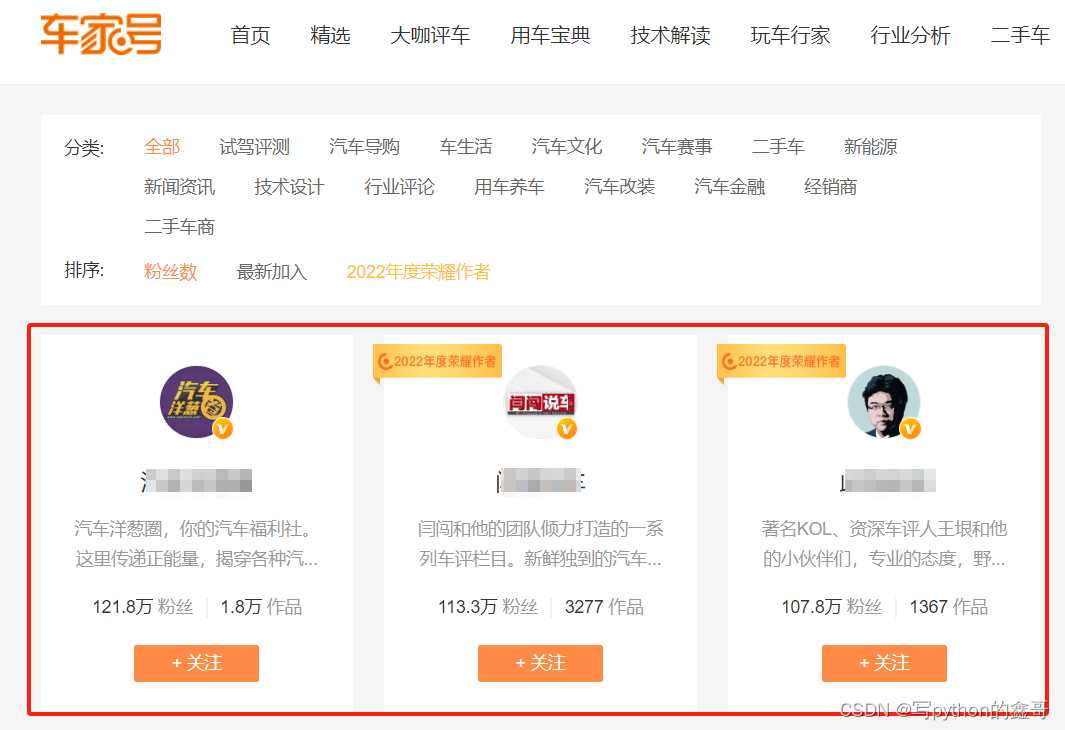
Python爬虫-获取汽车之家车家号
前言 本文是该专栏的第9篇,后面会持续分享python爬虫案例干货,记得关注。
地址:aHR0cHM6Ly9jaGVqaWFoYW8uYXV0b2hvbWUuY29tLmNuL0F1dGhvcnMjcHZhcmVhaWQ9MjgwODEwNA==
需求:获取汽车之家车家号数据 笔者将在正文中介绍详细的思路以及采集方法,废话不多说,跟着笔者直接往…

爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛
本着 “用技术改变生活” 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序
这篇文章,我们就来讲讲…
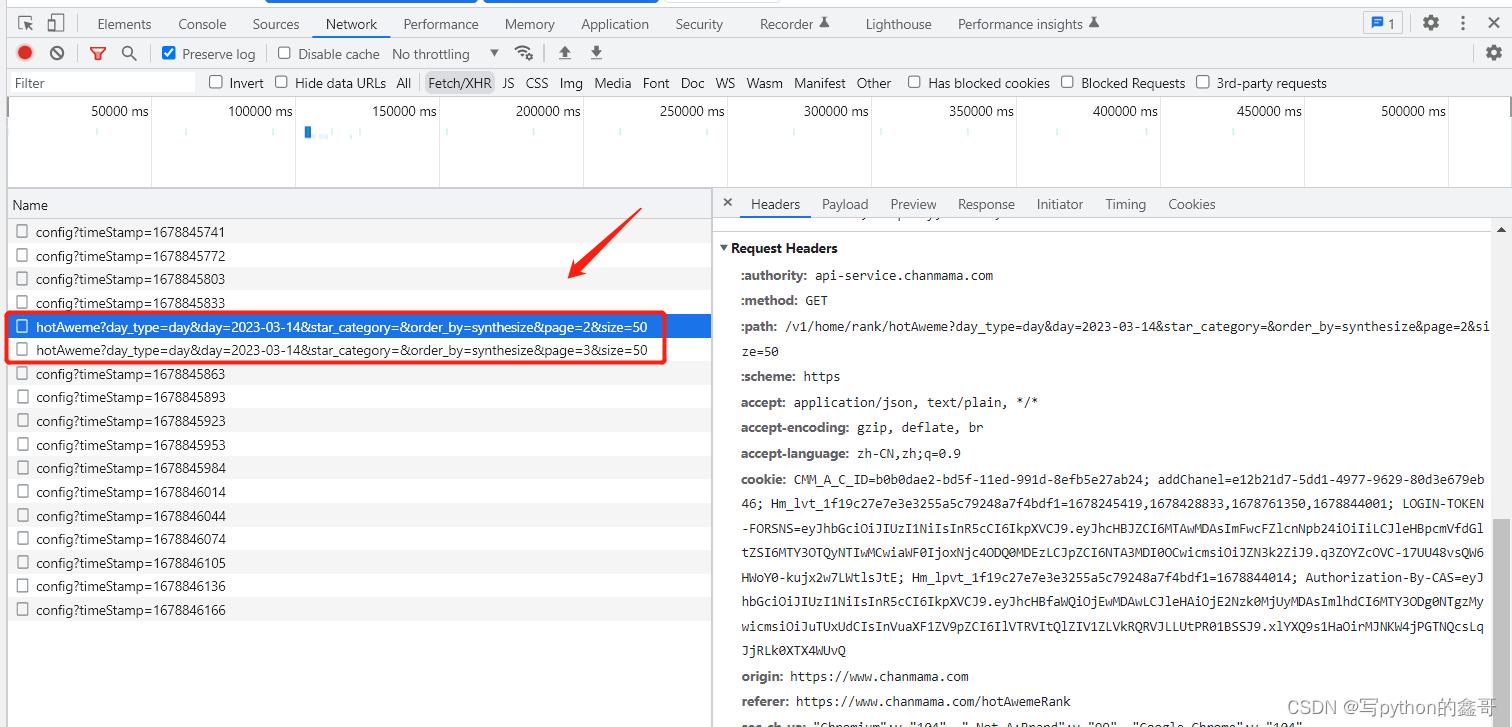
Python爬虫-蝉妈妈热门视频榜单
前言 本文是该专栏的第38篇,后面会持续分享python爬虫干货知识,记得关注。
通过蝉妈妈查看视频榜单数据的前提,首先需要账号登录才能正常看到榜单数据。榜单如下: 下面以热门视频榜为例,跟着笔者直接往下看。 正文 1. 参数分析
进入榜单页面之后,直接Ctrl+Shift+I快捷键…
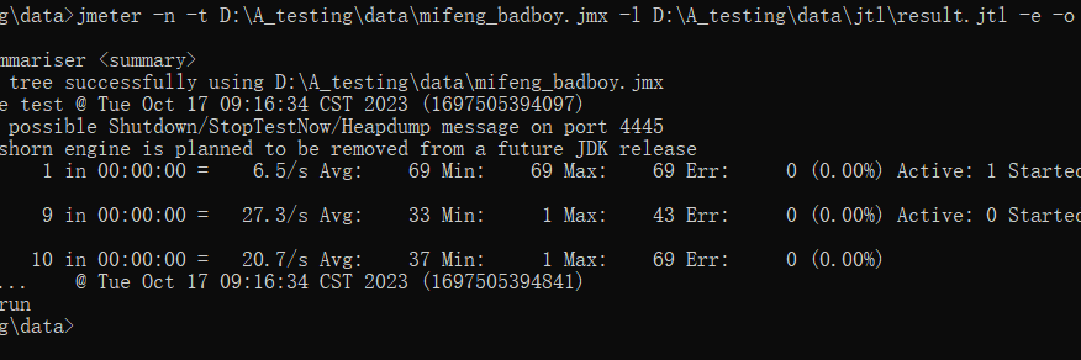
软件测试进阶篇----接口测试
接口测试
一、接口的概述 接口是什么? 在系统与系统之间、子系统与子系统之间数据交互的功能就是接口。 接口就是一个特定功能的函数(方法),有参数,有返回值,调用者需要通过某种方式(网络协议&…
Python+requests+lxml爬取豆瓣电影短评
# 1-数据 -- requests
"""
豆瓣指定电影短评---10页1-下载页面2-检索数据3-数据存储
"""
import requests
from lxml import html
def download(url):code requests.get(url).text # strcode html.fromstring(code)return codedef getvalues(…
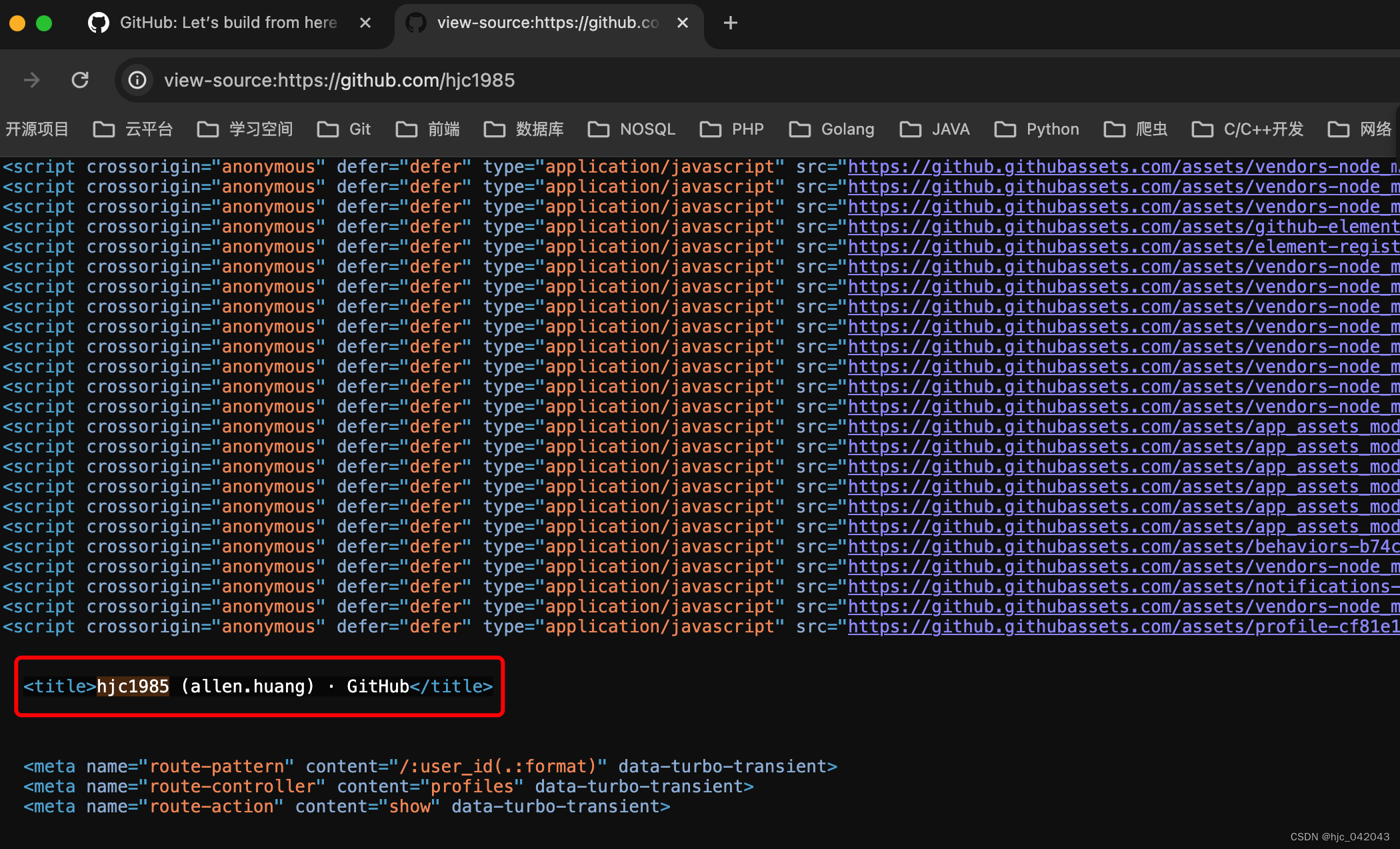
Python之requests实现github模拟登录
文章目录 github 模拟登录前言模拟登录流程抓包操作查看登录表单的内容登录操作 模拟登录操作在 main函数的调用获得 auth_token调用/session接口登录处理检测登录是否成功 总结: github 模拟登录
前言 前面学习了requests模块的基础学习后,接下来做一个…
Python脚本之requests发请求
本文为博主原创,未经授权,严禁转载及使用。 本文链接:https://blog.csdn.net/zyooooxie/article/details/128021167
分享下 在日常工作中 是如何使用requests来发请求的;
【实际这篇博客推迟发布N个月】
个人博客:h…
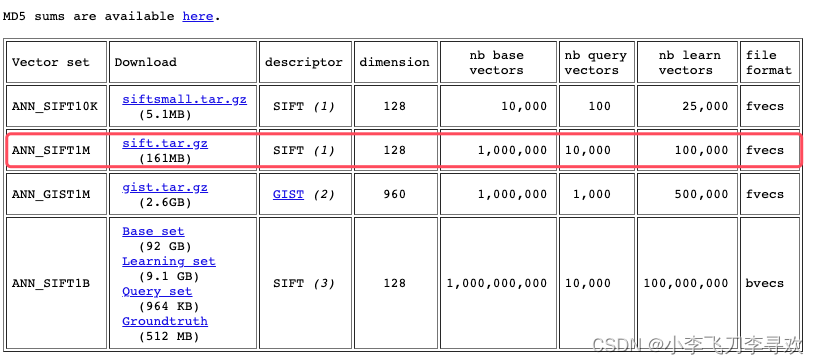
sift-1M数据集的读取及ES插入数据
sift是检查ann近邻召回率的标准数据集,ann可以选择faiss,milvus等库或者方法;sift数据分为query和base,以及label(groundtruth)数据。本文采用sift-1M进行解读,且看如下:
1、sift-1m数据集
官方链接地址:Evaluation of Approximate nearest neighbors: large datase…

Python爬虫技术详解:从基础到高级应用,实战与应对反爬虫策略【第93篇—Python爬虫】
前言
随着互联网的快速发展,网络上的信息爆炸式增长,而爬虫技术成为了获取和处理大量数据的重要手段之一。在Python中,requests模块是一个强大而灵活的工具,用于发送HTTP请求,获取网页内容。本文将介绍requests模块的…
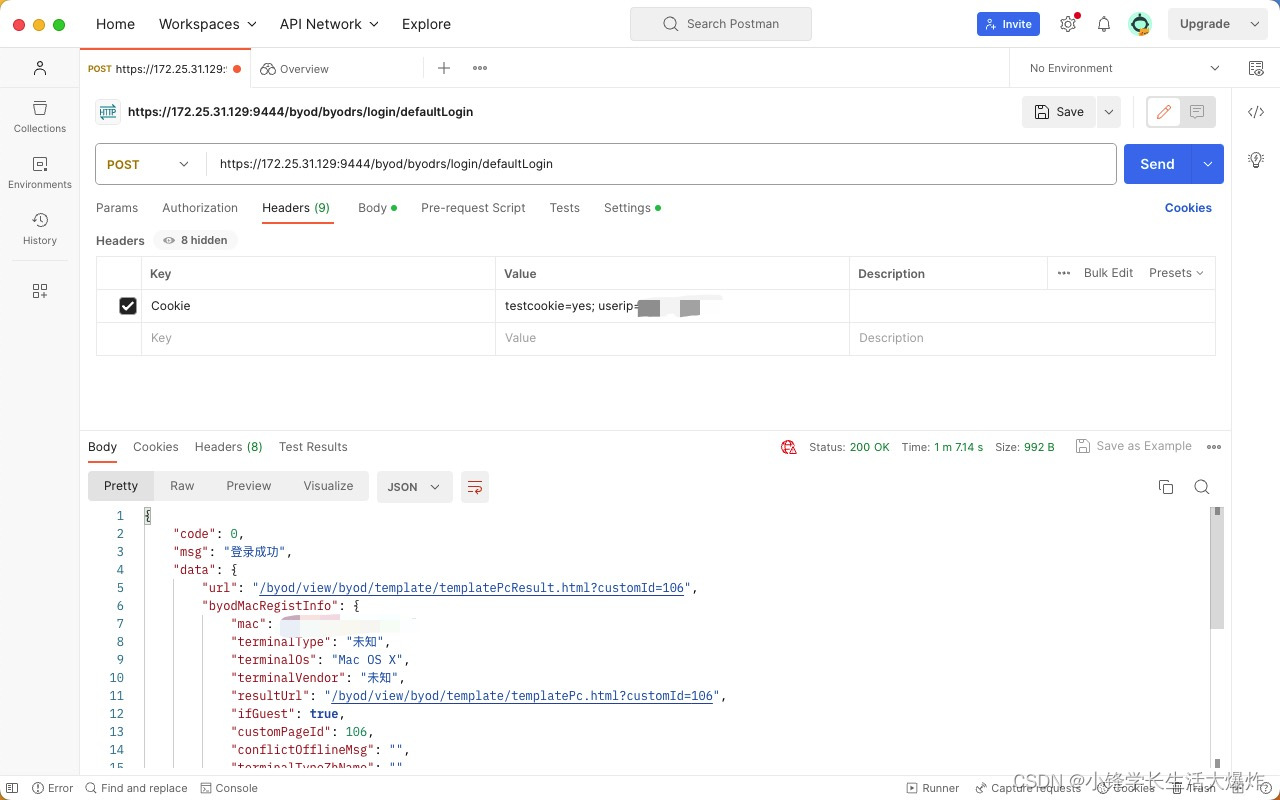
【教程】华南理工大学校园网登录抓包和协议模拟
每次手动登录特别麻烦,而且时不时断一下,因此搞个脚本让它定时监测、断开重连比较方便。这里不讲这个脚本怎么写,只记录一下登录时的抓包内容。 蒜了,直接上解析吧,也不复杂,相信大家一目了然。 目录
抓包…
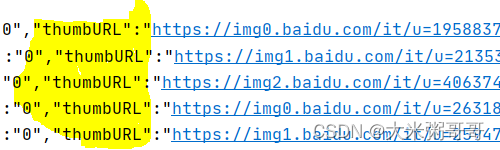
python 使用requests爬取百度图片并显示
爬取百度图片并显示 引言一、图片显示二、代码详解2.1 得到网页内容2.2 提取图片url2.3 图片显示 三、完整代码 引言
爬虫(Spider),又称网络爬虫(Web Crawler),是一种自动化程序,可以自动地浏览…

requests+正则表达式爬猫眼电影TOP100
爬取地址:http://maoyan.com/board/ 提示:很抱歉,您的访问被禁止 需要伪装浏览器,在headers中添加’User-Agent’字典内容 headers {User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like…
pytest测试框架介绍(2)
继续进步一点点,温故而知新
一、requests 介绍
1、requests 的官方文档:https://docs.python-requests.org/en/latest/
2、安装requests:pip install requests
二、requests请求
1、请求方法:post,get,…

解决python2.7.9版本requests访问https的问题
本人在linux下搭建python项目时,刚好需要通过python中的requests.post()方式去获取微信的openid,但是一直报如上截图出现的错误,我用的python版本是2.7.9
TypeError: MaxRetryError("HTTPSConnectionPool(hostapi.weixin.qq.com, port443): Max ret…
1-爬虫-requests模块快速使用,携带请求参数,url 编码和解码,携带请求头,发送post请求,携带cookie,响应对象, 高级用法
1 爬虫介绍 2 requests模块快速使用 3 携带请求参数 4 url 编码和解码 4 携带请求头 5 发送post请求 6 携带cookie 7 响应对象 8 高级用法 1 爬虫介绍
# 爬虫是什么?-网页蜘蛛,网络机器人,spider-在互联网中 通过 程序 自动的抓取数据 的过程…
使用requests发请求操作Elasticsearch【二】
本文为博主原创,未经授权,严禁转载及使用。 本文链接:https://blog.csdn.net/zyooooxie/article/details/118367832
前面刚刚分享 使用requests发请求操作Elasticsearch【一】 ,继续分享下。
【实际这篇博客推迟发布N个月】
个…

Python 简单爬虫实例
目录
摘要
1.确定爬取网页对象
1.1查看目标对应的源码
2.获取网页源代码
3.解析网页源码
结束 摘要
本文主要介绍使用python第三方库beautifulsoup及requests实现网页内容抓取,以百度首页为例,介绍如何从零开始介绍如何抓取指定网页中的内容。
1…
python requests库发送接口请求,小白必会!!!
import requests
import json#发送get请求并得到结果
url = http://api.nnzhp.cn/api/user/stu_info?stu_name=小黑马 #请求接口
req = requests.get(url)#发送请求
print(req.text)#获取请求,得到的是json格式
print(req.json())#获取请求,得到的是字典格式
print(type(req…

Python爬虫-D车网近半年(六个月)汽车销量排行榜
前言 本文是该专栏的第46篇,后面会持续分享python爬虫干货知识,记得关注。
在本专栏前面,笔者有单独详细介绍过该平台当前月更新的最新汽车销量排行榜数据。感兴趣的同学,可往前翻阅查看(Python爬虫-某懂车平台之汽车销量排行榜)。
而本文,笔者将详细来介绍该平台近半年…
Backend - Python 序列化
目录
一、作用
(一)代码块存入数据库
(二)前后端传递数据
1. 前端
(1)JSON.stringify()
(2)JSON.parse()
2. 后端
(1)json.dumps()
(2&a…
开启VPN使用爬虫,报错requests.exceptions.SSLError
报错信息
requests.exceptions.SSLError: HTTPSConnectionPool(hosthttps://www.youtube.com/, port443):
Max retries exceeded with url: / (Caused by SSLError(SSLEOFError(8, EOF occurred in violation
of protocol (_ssl.c:1125))))原因
urllib3 1.26之后更新了主架…
Python requests之Session
视频版教程:一天掌握python爬虫【基础篇】 涵盖 requests、beautifulsoup、selenium
在 requests 里,session对象是一个非常常用的对象,这个对象代表一次用户会话:从客户端浏览器连接服务器开始,到客户端浏览器与服务…
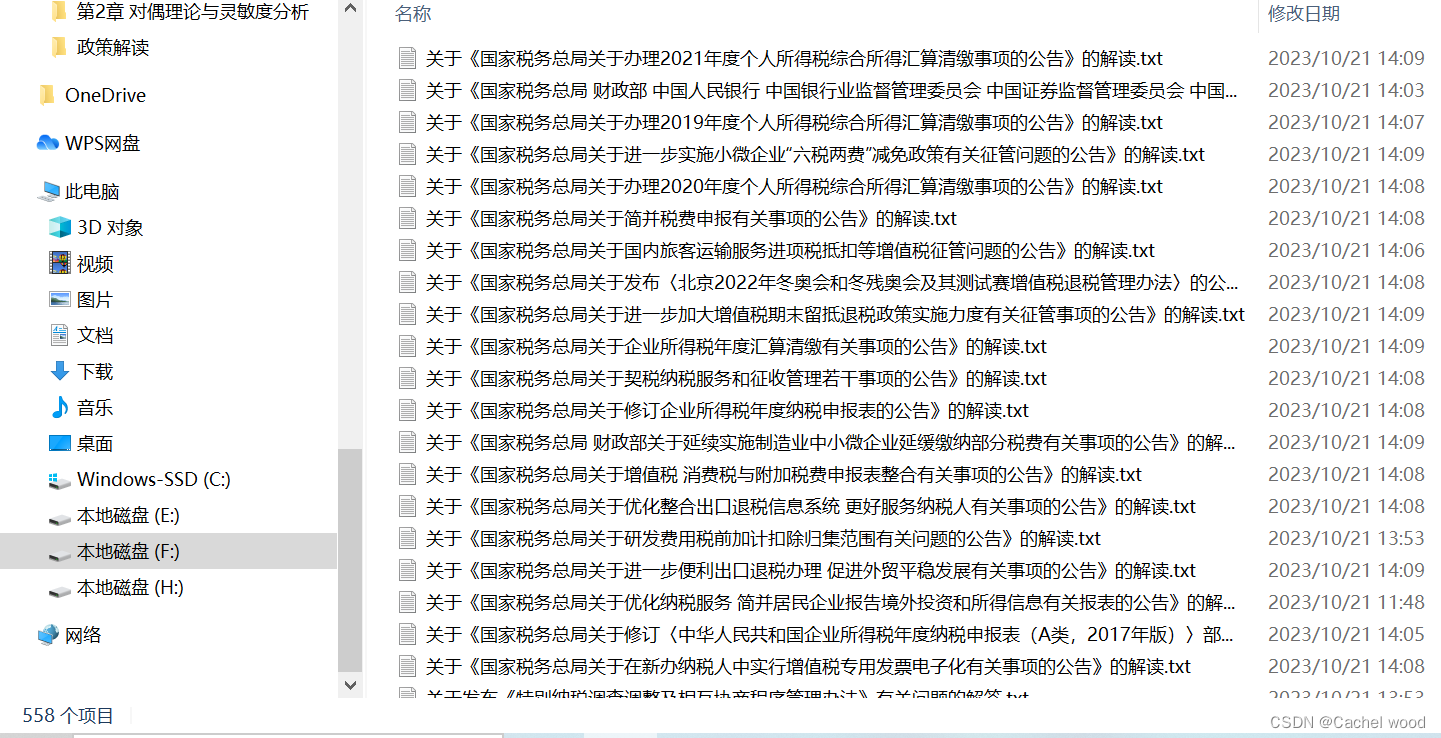
python requests爬取税务总局税案通报、税务新闻和政策解读
文章目录 环境配置页面爬取流程税案通报爬取code税务新闻爬取政策解读爬取 环境配置
python:3.7 requests:发出请求,返回页面 beautifulsoup:解析页面 time:及时 warnings:忽视警告
页面
网址࿱…